 In my last post, I user some back-of-the-envelope reliability calculations, with just one interesting bit, to estimate the availability of a single-stacked web application, shown again here. I cautioned that there were a lot of unfounded assumptions baked in. Now it's time to start removing those assumptions, though I reserve the right to introduce a few new ones.
In my last post, I user some back-of-the-envelope reliability calculations, with just one interesting bit, to estimate the availability of a single-stacked web application, shown again here. I cautioned that there were a lot of unfounded assumptions baked in. Now it's time to start removing those assumptions, though I reserve the right to introduce a few new ones.
Is it there when I want it?
First, lets talk about the hardware itself. It's very likely that these machines are what some vendors are calling "industry-standard servers." That's a polite euphemism for "x86" or "ia64" that just doesn't happen to mention Intel. ISS servers are expected to exhibit 99.9% availability.
There's something a little bit fishy about that number, though. It's one thing to say that a box is up and running ("available") 99.9% of the times you look at it.If I check it every hour for a year, and find it alive at least 8,756 out of 8,765 times, then it's 99.9% available. It might have broken just once for 9 hours, or it might have broken 9 times for an hour each, or it might have broken 36 times for half an hour each.
This is the difference between availability and reliability. Availability measures the likelihood that a system can perform its function at a specific point in time. Reliability, on the other hand, measures the likelihood that a system will have failed before a point in time. Availability and reliability both matter to your users. In fact, a large number of small outages can be just as frustrating as a single large event. (I do wonder... since both ends of the spectrum seem to stick out in users' memories, perhaps there's an optimum value for the duration and frequency of outages, where they are seldom enough to seem infrequent, but short enough to seem forgivable?)
We need a bit more math at this point.
It must be science... it's got integrals.
Let's suppose that hardware failures can be described as function of time, and that they are essentially random. It's not like the story of the "priceless" server room, where failure can be expected based on actions or inaction. We'll also carry over the previous assumption that hardware failures among these three boxes are independent. That is, failure of any one boxes does not make other boxes more likely to fail.
We want to determine the likelihood that the box is available, but the random event we're concerned with is a fault. Thus, we first need to find the probability that a fault has occurred by time t. Checking for a failure is sampling for an event X between times 0 and t.
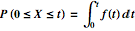
The function f(t) is the probability distribution function that describes failures of this system. We'll come back to that shortly, because a great deal hinges on what function we use here. The reliability of the system, then is the probability that the event X didn't happen by time t.
![]()
One other equation that will help in a bit is the failure rate, the number of failures to expect per unit time. Like reliability, the failure rate can vary over time. The failure rate is:
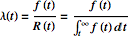
Failure distributions
So now we've got integrals to infinity of unknown functions. This is progress?
It is progress, but there are some missing pieces. Next time, I'll talk about different probability distributions, which ones make sense for different purposes, and how to calibrate them with observations.